
Fonte : Algorithmwatch.org che ringraziamo
Una prima analisi mostra che le piattaforme hanno fatto ben poco per “potenziare la comunità di ricerca” nonostante le promesse fatte lo scorso giugno nell’ambito del rinnovato Codice di condotta sulla disinformazione dell’UE.
Giovedì scorso, dozzine di aziende tecnologiche, comprese le principali piattaforme di social media come Facebook, YouTube, TikTok e Twitter, hanno pubblicato i primi rapporti di base intesi a dettagliare i loro sforzi per combattere la disinformazione nell’UE.
I rapporti, che sono disponibili al pubblico , parlano dei progressi delle piattaforme su una litania di impegni presi a luglio nell’ambito del Codice di condotta sulla disinformazione del 2022 . Ciò include, tra le altre cose, promesse sulla demonetizzazione della disinformazione, sulla trasparenza degli annunci politici, sulla collaborazione con i verificatori di fatti e sull’agevolazione dell’accesso dei ricercatori ai dati.
Sebbene il codice sia volontario, i suoi impegni potrebbero diventare vincolanti per le piattaforme più grandi una volta che la Commissione europea inizierà a monitorarli e applicarli quest’estate ai sensi del Digital Services Act (DSA). Per aver violato il DSA, le piattaforme Big Tech con oltre 45 milioni di utenti nell’UE potrebbero incorrere in multe fino al 6% dei loro ricavi globali: adempiere ai loro impegni ai sensi del codice di condotta è un modo per alleggerire i loro obblighi di conformità.
Quindi come hanno fatto? Non così bene, secondo le ONG e i gruppi di verifica dei fatti strettamente coinvolti e che monitorano il Codice. Twitter è stato ampiamente criticato per aver inviato un rapporto incompleto e i progressi delle altre principali piattaforme sono stati decisamente contrastanti.
In particolare, quando si tratta di fornire ai ricercatori un migliore accesso ai dati, i critici e Věra Jourová, vicepresidente della Commissione europea per il valore, concordano sul fatto che i rapporti lasciano molto a desiderare .
Ci sono alcuni indicatori positivi in questo settore: ad esempio, le principali piattaforme (tranne Twitter) hanno affermato di sostenere attivamente l’Osservatorio europeo dei media digitali (EDMO) nello sviluppo di un organismo indipendente per consentire la condivisione sicura dei dati con ricercatori indipendenti. Ma in generale, le piattaforme hanno finora segnalato poche preziose misure concrete per sostenere le loro promesse.
Questa analisi iniziale approfondisce i rapporti per esaminare ciò che le rivelazioni di Facebook, TikTok, YouTube e Twitter dicono – e non dicono – sui loro sforzi per “potenziare la comunità di ricerca”.
Facebook e Instagram
Una vasta gamma di sforzi per la trasparenza non può coprire la lenta morte di CrowdTangle
Nel descrivere i suoi impegni nei confronti dei ricercatori, il rapporto di Facebook è scarso nel fornire fatti e cifre concreti. In tal senso, questo rapporto di “baseline” non offre molto di una linea di base oltre a indicare i programmi esistenti e riformulare le divulgazioni che sono già pubbliche.
Detto questo, il rapporto di Facebook copre un assortimento relativamente ampio di programmi di ricerca esistenti e rapporti sulla trasparenza che la società pubblica trimestralmente. Indica inoltre la sua API Ad Library che consente ai ricercatori di cercare dati relativi agli annunci e una piattaforma di ricerca per condividere dati con ricercatori indipendenti selezionati per studiare “comportamenti non autentici coordinati”, ovvero campagne online che cercano di manipolare il dibattito pubblico.
Tuttavia, c’è un’evidente omissione nel rapporto di Facebook.
La relazione segue la struttura del codice, che contiene 44 impegni e 128 misure specifiche. In Commitment 26, i firmatari promettono API che consentono ai ricercatori di cercare e analizzare i dati pubblici in tempo reale, il che è già possibile tramite CrowdTangle di Facebook, uno strumento di analisi dei dati che i ricercatori utilizzano per monitorare la disinformazione che circola su Facebook e Instagram.
Ciò che manca dal rapporto di Facebook, quindi, sono misure concrete sui livelli di diffusione, rapidità e accettazione di CrowdTangle, il che è chiaro guardando questo grafico:
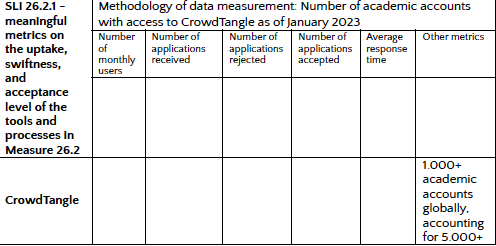
Perché il tavolo vuoto? È probabile perché CrowdTangle è in fase di eliminazione, come riportato lo scorso anno, e il programma ha smesso da tempo di accettare nuovi candidati.
Una volta che CrowdTangle se ne sarà andato, la domanda è come Facebook intende sostituirlo in linea con i suoi impegni nel codice e se una vasta gamma di ricercatori sarà in grado di accedere a tali strumenti (inclusi ricercatori e giornalisti della società civile). L’azienda ha lanciato una nuova API di ricerca , ma al momento è disponibile solo per gli accademici selezionati manualmente da Facebook.
TikTok
L’azienda di proprietà cinese ha un track record più breve in materia di trasparenza e un ulteriore onere della prova
Essendo la più giovane delle principali piattaforme di social media ad aver firmato il codice, TikTok non ha una lunga storia di trasparenza, ed è un argomento delicato per l’azienda, dati i timori che l’influenza dello stato cinese possa corrompere l’app (TikTok è di proprietà di ByteDance , una società cinese). Egregiamente, TikTok ha ammesso a novembre di aver utilizzato la sua app per spiare i giornalisti nel tentativo di scoprire la fonte delle fughe di notizie dall’interno dell’azienda.
TikTok ha comunque fatto annunci appariscenti nel tentativo di placare gli scettici. La società prevede di aprire un Transparency Center per la moderazione e le pratiche sui dati a Los Angeles e promette di rendere disponibile il suo codice sorgente per l’ispezione (il centro è già stato visitato da giornalisti selezionati ; si dice che un’apertura completa sia ritardata a causa della pandemia) . TikTok ha anche annunciato un’imminente API per i ricercatori in linea con l’impegno 26 del codice di condotta (a differenza di Facebook e Twitter, che hanno già stabilito API per i ricercatori, TikTok ha almeno una scusa per non essere in grado di riportare le metriche di base sulla sua API come non è ancora stato lanciato).
Nell’Azione 28, i firmatari promettono anche di sostenere la ricerca in buona fede sulla disinformazione che coinvolge i loro servizi. A tal fine, TikTok sottolinea il suo Consiglio consultivo e di sicurezza europeo formato nel 2021, la partecipazione dei suoi rappresentanti a eventi incentrati sulla ricerca e l’impegno generale con la comunità di ricerca.
Un aspetto cruciale di questo impegno è la promessa delle piattaforme di non proibire o scoraggiare la ricerca di interesse pubblico sulla disinformazione sulle loro piattaforme e di non intraprendere azioni contraddittorie contro utenti o account ricercatori che intraprendono o partecipano a ricerche in buona fede. Adempiere a questo impegno si pentirebbe del comportamento passato di Facebook nel mettere la museruola alla ricerca di interesse pubblico dell’Osservatorio pubblicitario della NYU e di AlgorithmWatch . Vedremo come TikTok risponde al progetto di donazione di dati lanciato di recente da AlgorithmWatch per studiare il feed di raccomandazione “For You” di TikTok.
Ricerca Google e YouTube
Google mostra alle altre piattaforme come viene svolto un esercizio di selezione delle caselle
Ciò che salta fuori nel rapporto di Google è un’apparente volontà di seguire il copione stabilito dal codice di condotta, non solo riportando i suoi vari impegni, ma fornendo almeno alcune metriche di base generali.
Innanzitutto, Google descrive i suoi strumenti di ricerca pubblicamente disponibili, tra cui Google Trends e Fact Check Explorer , e fornisce dati effettivi (se non verificati) sul numero di utenti di ciascuno strumento, suddivisi per stato membro dell’UE. La società condivide anche alcuni numeri approssimativi relativi all’adozione del suo programma di ricerca su YouTube , lanciato nel luglio 2022. Questo programma promette di espandere l’accesso ai metadati video globali di YouTube tramite un’API per i ricercatori accademici, ma con meno di 15 ricercatori unici che hanno avuto accesso all’API finora, YouTube ha dati granulari minimi da riferire su di esso.
Google prosegue citando i suoi sforzi filantropici per illustrare il suo impegno a sostenere la ricerca in buona fede sulla disinformazione. Ciò include la donazione di 25 milioni di euro della società per aiutare a lanciare il Fondo europeo per i media e l’informazione , che fornisce sovvenzioni a progetti volti ad aumentare l’alfabetizzazione mediatica e combattere la disinformazione online. Google afferma di non avere alcun ruolo nella valutazione delle domande di sovvenzione. Ma la comunità di ricerca dovrebbe essere cauta nell’accettare i soldi dell’azienda, per evitare che Google invada l’indipendenza della ricerca così come intrappola il giornalismo .
Niente di tutto ciò significa che Google abbia presentato un rapporto esemplare quando si tratta dell’accesso dei ricercatori ai dati. L’azienda ha ancora molto lavoro da fare per espandere il suo nuovo programma di ricerca di punta, ad esempio, e fornire informazioni più granulari sui suoi strumenti di ricerca. Ma questo rapporto di base brilla praticamente rispetto alle altre piattaforme principali, dato quanto è stato impostato il livello basso, con nessuno inferiore alla piattaforma finale in questo elenco.
Twitter
Un tempo leader nella ricerca sulle piattaforme, i programmi dell’azienda sono diventati AWOL sotto Elon Musk
Il primo rapporto sull’implementazione di Twitter è tristemente incompleto . È ottuso anche per quanto riguarda i suoi impegni nella ricerca di interesse pubblico. L’azienda si vanta di essere un leader del settore nell’accesso ai dati, ma sotto Elon Musk l’azienda ha di fatto smantellato o interrotto l’accesso a praticamente tutti i suoi programmi di ricerca.
Ad esempio, Twitter evidenzia il Twitter Moderation Research Consortium , che ha condiviso i dati con ricercatori esterni controllati per far luce sulle campagne di informazione sostenute dallo stato condotte sulla piattaforma. Ma il programma si è oscurato a novembre una volta che il team che gestiva il progetto è stato sventrato.
Twitter si collega anche a ricerche precedenti che la società ha svolto su questioni come il pregiudizio politico nelle raccomandazioni sui contenuti algoritmici. Il problema è che anche la maggior parte del team responsabile di questa ricerca, il cosiddetto team ” Ethical AI ” di Twitter, è stato licenziato a novembre.
Infine, Twitter rileva il suo programma API di lunga data a cui i ricercatori possono richiedere l’accesso. Tuttavia, la società ha iniziato il paywalling della sua API a partire dal 13 febbraio, ponendo un nuovo onere finanziario sui ricercatori di interesse pubblico e interrompendo di fatto l’accesso a coloro che non possono permetterselo.
Limitare la sua API è un altro passo indietro per la conformità di Twitter al codice di condotta. La mossa ha costretto oltre 100 organizzazioni di ricerca e oltre 500 persone a firmare una lettera aperta chiedendo a Twitter di garantire che la sua API rimanga facilmente accessibile a giornalisti, accademici e società civile e invitando i responsabili politici a richiedere che questa infrastruttura vitale rimanga facilmente accessibile.
Sulla base di queste prove, tutto ciò che Twitter dice sul suo “impegno” nella ricerca di interesse pubblico e sulla sua disponibilità a rispettare le normative dell’UE potrebbe essere giustamente descritto come un ” brutto scherzo “.
I secondi rapporti previsti per luglio dovrebbero essere oggetto di un esame più approfondito
Uno degli obiettivi del codice di condotta è garantire che i ricercatori indipendenti siano potenziati, piuttosto che combattuti, dalle piattaforme dei social media. Questo perché consentire ai ricercatori di analizzare i dati della piattaforma è uno dei modi migliori per comprendere la diffusione della disinformazione online e altri potenziali rischi che i social media rappresentano per gli individui e la società.
Eppure gli approcci delle piattaforme ai ricercatori indipendenti, come evidenziato dalle loro azioni, non dalle loro parole, sono stati nel migliore dei casi disomogenei e nel peggiore dei casi apertamente ostili. Sulla base di questi primi rapporti di base, sembra che le piattaforme abbiano fatto pochi progressi nei loro approcci (nel caso di Twitter e CrowdTangle di Facebook, c’è stata una notevole regressione nei confronti dei ricercatori).
Dovremmo aspettarci un’indicazione più completa degli sforzi delle principali piattaforme a luglio, quando arriverà il secondo ciclo di rapporti sull’implementazione. I dati forniti in tali relazioni dovrebbero essere soggetti a un grado di controllo molto più elevato, anche da parte di revisori e ricercatori indipendenti nell’ambito del quadro di accesso ai dati del DSA .
Il fatto che le piattaforme rispettino i propri impegni ai sensi del codice di condotta dipenderà dall’applicazione della Commissione europea, che ha il potere di emettere multe elevate contro le piattaforme più grandi per il mancato rispetto di determinati impegni del codice e, per estensione, il DSA. La Commissione potrebbe avviare indagini su potenziali violazioni dei DSA già nel settembre 2023.